














Among providers serving the flagship open-source model from Moonshot AI, CoreWeave delivers the highest token throughput with lowest latency delivering best price performance.
In the rest of this post, we explain what that means for your workloads and take a technical look at the optimizations behind CoreWeave Inference.
Kimi K2.6 is one of the best open-source models
Kimi K2.6 is Moonshot AI’s flagship open-source model, released on April 20, 2026. It is one of the most widely used open-weight models, ranking #2 on OpenRouter’s leaderboards. It is a 1-trillion-parameter Mixture-of-Experts (MoE) model with 32 billion active parameters per token, native multimodal input, and a 262K context window.
K2.6 is competitive with leading proprietary frontier models, scoring 86.3 on BrowseComp, 80.2 on SWE-Bench Verified, and 66.7 on Terminal-Bench 2.0. It has quickly become a favored model for coding agents and multi-step agent frameworks.
CoreWeave leads in Artificial Analysis benchmarks for Kimi K2.6
Artificial Analysis evaluates the two metrics that matter most to production teams: output speed in tokens per second, and price per million tokens (a 7:2:1 blend of cache-hit, input, and output costs). The "most attractive" quadrant is high speed, low price. CoreWeave is the only inference provider for Kimi K2.6 in the most attractive quadrant today.
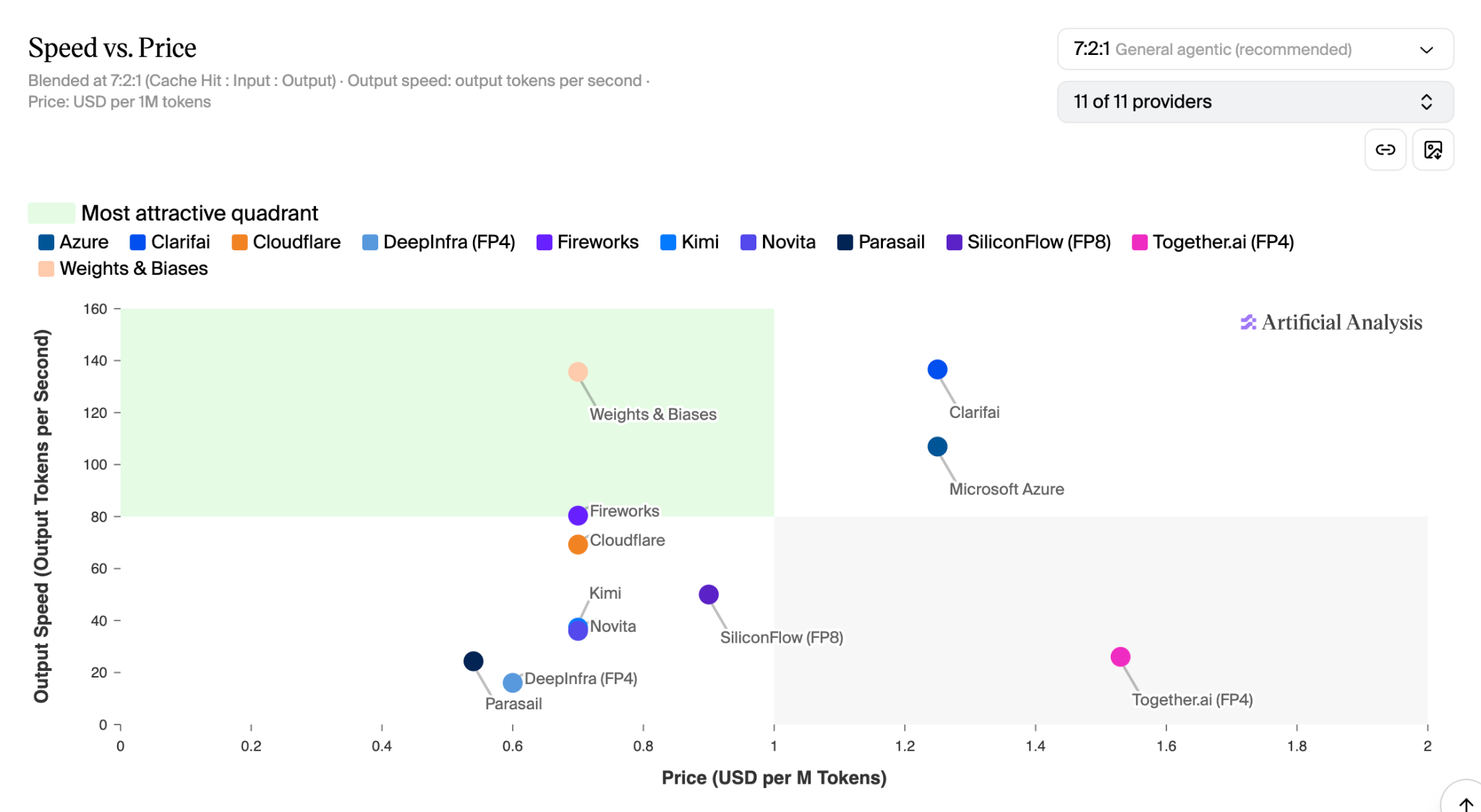
The winning optimization: training and deploying NVFP4 and EAGLE3 on NVIDIA GB300
The CoreWeave Applied Training team, an internal research group of domain experts, leverages our NVIDIA GB300 and GB200 NVL72 clusters alongside advanced optimization techniques, including NVIDIA Model Optimizer PTQ, to train and fine-tune the latest AI models. Every experiment is supported by rigorous quality and accuracy evaluations using Weights & Biases and modern test harness frameworks.
Training a custom NVFP4 quantized model in addition to EAGLE3 speculative decoding led to the greatest performance gains on Kimi K2.6. We also validated the quality of the model across a range of notable benchmarks including Terminal-Bench 2.0, SWE-Bench Verified, SWE-Bench Pro, GPQA Diamond, AIME 2026, and LiveCodeBench v6. Validating the NVFP4 weights across these benchmarks is essential in improving model performance without degrading quality.
Beyond model-level optimization, CoreWeave integrates performance enhancements throughout every layer of the CoreWeave Inference stack. From bare-metal access to the latest NVIDIA accelerators and high-speed interconnects to optimized memory architectures and custom inference stack tuning, CoreWeave is engineered to deliver industry-leading inference performance.
Why price-performance matters for inference as enterprises scale AI
In production inference, every lever that improves performance also impacts cost: GPU selection, quantization, attention backend, KV cache layout, batch sizing, speculative decoding and kernels. Real-time customer facing workloads demand low latencies, while offline workloads such as evaluations demand high throughput at low cost. CoreWeave Inference allows customers to tune cost-performance for each workload, with flexible options from token-based consumption to GPU-based scaling.
Serverless Inference provides the fastest path to deployment, enabling developers to access a broad selection of models through a single unified API. Dedicated Inference offers greater flexibility by allowing customers to optimize performance with explicit GPU selection, runtime configuration, and auto-scaling, while CoreWeave manages the underlying infrastructure. For maximum control, Inference on CKS gives customers direct control over GPUs, runtimes, orchestration, and capacity management.
Try Kimi K2.6 on CoreWeave Inference now
Learn more about CoreWeave Inference











